LUKS, VeraCrypt, CryFS, EncFS, gocryptfs...? A practical discussion on sync of encrypting files



This article provides a brief discussion of the types of cryptography available at the ‘day to day’ level and the implications of its use, both locally and in the cloud. Advanced technical procedures regarding the theoretical functioning of the mentioned types were not addressed here.
Well, the first thing we usually think about when we are going to encrypt something, be it a file or folder, is to know what password will be entered, or am I wrong? While this seems to give the impression of being the only valuable information, the way you will produce and manage this encrypted file will much more direct the life cycle of your file, like where you can transport it or how it will grow over time. over time.
There are basically two basic types of encryption: full volume e adaptive volume. Both are described in many software as volumes or containers. This denomination was created by me, in this text, as a pedagogical method to help in the following explanation.
But what is the difference between them?
Full volume encryption works by creating a volume with a predefined size, as if it were a mini block device (like a pendrive). For example, with it it is possible for the user to create a fixed size file that can be opened in the operating system and receive data writing. This process is noticed, for example, when a hard disk partition is encrypted during the installation of the OS, where before it loads, it will call a window for the user to enter the decryption password, after which the volume will be mounted as file system and can be used by the user. Similarly, you can have multiple volumes in any directory on your operating system, so mount and unmount them at any time.
The most common types of full volume encryption are: LUKS, Veracrypt, Truecrypt and PLAIN dm-crypt.
Adaptive volume encryption, as well as the auto name explanatory, works by recording each piece separately within the created volume, and grows continuously, as if it were literally a folder in the system. The difference between the first is that it is not necessary for the user to define the volume size at the time of creation, but it will grow over time, adaptively.
The most common types of adaptive volume encryption are: CryFS, gocryptfs and EncFS.
Well, by now you should have done a brief summary of what I wrote and probably the result brings a previous concept: the disk space.
This space is a crucial point that must be taken into account when creating encrypted volumes. To make it a little clearer, I will work on this issue with examples from day to day.
Imagine that you have a 10GB cloud repository, available on the Dropbox service. Consequently, you know that you can synchronize all that there. So, if you choose to create a full volume encrypted file on your operating system, you will have to specify its size. Let’s say you put 5GB. So, after creating and the first synchronizing the volume to the dropbox server, you spent 5GB of bandwidth and probably caused a delay and slow uploading on your network. Now, imagine right after that you mount the volume on the operating system and create a 10KB text file inside and then close it. The sync service will consider that volume as an altered single block, and since it is encrypted, the dropbox has no way of knowing what this is and neither does version control. What is he going to do? Synchronize the same 5GB again. Too bad huh? Almost impractical.
It is in this case that the encryption systems that work with adaptive volumes fit like a glove. First, that when creating such a volume it is not necessary to specify its previous size, therefore, it will have almost zero disk space used. So, starting from the same example, but now with an adaptive volume, the first sync would probably take a few seconds. If you created a text file with the same 10KB within the volume, the dropbox service would recognize the changed blocks and send them only, adaptively. This means that the second synchronization would cost you much less upload bandwidth. Much better, right?
Finally, one last addendum. In full volume encryption, the volume size defined at the time of its creation is fixed throughout its life and cannot be changed. Already with the adaptive volume, it will grow continuously, and what will define its total size, in fact, will be how much you will write inside it.
In short, the cost of using encryption to sync in the cloud will depend on the type of encryption chosen. If you choose wrong, it will have disastrous consequences. Therefore, if working with full volume to synchronize in the cloud, I recommend creating small volumes, otherwise, it adopt the adaptive volume encryption.
Below are two images. The first is an act of creating a full volume and the second an adaptive volume.
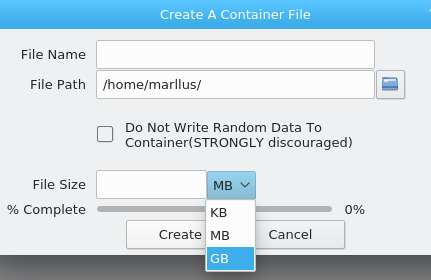
Full volume encryption: you have to specify the previous size
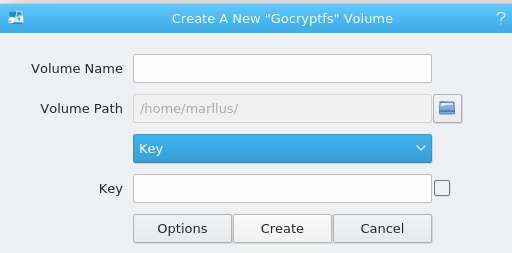
Adaptive volume encryption: the total size will be defined with the number of files over time
You might be wondering why not just use adaptive volume encryption, as it looks very good as it can be easily synced to a repository in the cloud. Well, it is a pertinent question and that would deserve another article with discussions regarding the utility, the restrictions, the desired levels of privacy, types of files and places of synchronization. But, I end here with the suggestion of two tools with very cool window interfaces for creating and managing encrypted volumes ‘full’ and ‘adaptive’. The first is ZuluCrypt/ZuluMount, which works with LUKS and VeraCrypt (recommended) and the second is Sirikali, which manages adaptive volumes, such as CryFS and gocryptfs (recommended).
Questions about security and efficiency of the mentioned encryption algorithms must be considered. Here on the CryFS project website you can read a great text about it, in addition to the points listed in this article. For more information on performance, I recommend a comparison made on the gocryptfs project website.
Thanks!
:)